【PAD】結論、PADでWEBページから情報を取得するなら「ページソースの取得」と「テキストの解析(正規表現)」だけわかればよいかも【RPA|Power Automate Desktop】

Desktop Computer Stock photos by Vecteezy
みなさん、こんにちは!
そーちゃん(@black777cat)です。
Power Automate Desktopを使ってWebから情報を取得していておもったことを書いていきます
用意されているWebからデータ抽出がめんどくさい
直感的で、数カ所の取得であればよいのですが、大量に取得しないと行けない場合や、少し特殊な情報が欲しい場合など対応がサクッとできません。
慣れの問題もあるとは思いますが、正直なところ現状使いにくいなと思います。
ソースコードから正規表現で必要なところを取り出せばよくない?
解決策としてはだったら、ソースコードから情報を取れば良いのでは?と思い調べたところ
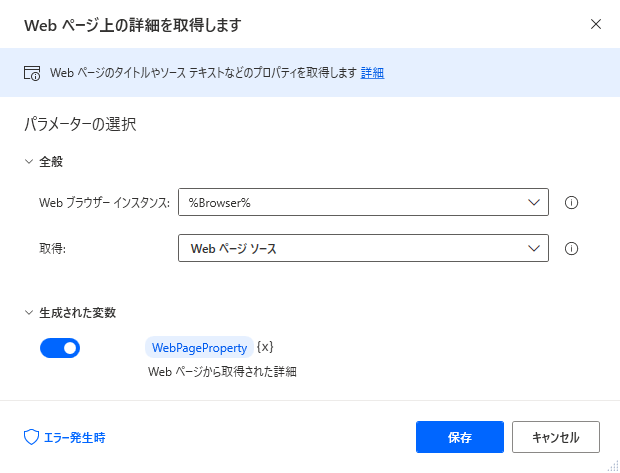
Webオートメーション > Webデータ抽出 > Webページ上の詳細を取得します
から取得できることがわかりました。
また同様に、
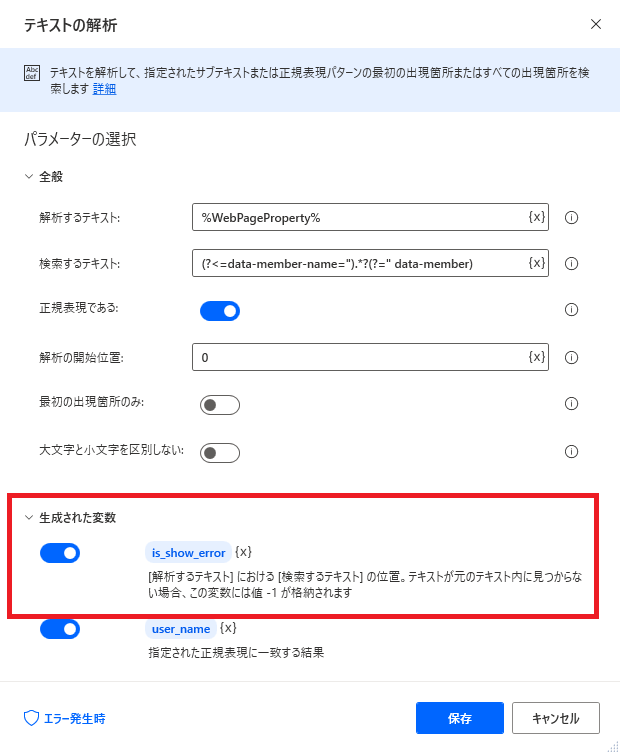
テキスト > テキストの解析
こちらの機能を使用することで、正規表現でデータを取得することが可能です。
これであれば、大抵の情報は拾えます。便利。
なお赤枠で囲った生成された変数についてですが、正規表現で取得できなかった場合に-1が返ってくるとありますが、実際には空文字が返ってきます。(執筆時点)
エラー処理の際などお気をつけください
それって他のプログラミング言語でもできるんじゃない?
そうなんです。
しかも他の言語のほうがブラウザを立ち上げる時間や処理時間が高速な場合が多いです。
GASやPython、PHPなんかでもウェブページを取得することは可能で、正直あんまりPADで処理するメリットは無いように思います。
それでもPADで処理するメリット
- 視覚的に順番に処理されているのがわかりやすい。
- ログインが必要なサイトをかんたんに処理できる。
- ブラウザ以外のアプリケーションとの連動可能。
この3点でしょうか。
特に2は大きくてGASで処理することもできなくは無いのですが、かなりめんどくさいので、良いかなーと思います。
まとめ
以上、結論、PADでWEBページから情報を取得するなら「ページソースの取得」と「テキストの解析(正規表現)」だけわかればよいかもと思ったので記事にしてみました。
実際にはケースバイケースだとは思いますので、うまく使っていきましょう。
ここまで読んでいただきありがとうございました。